RAG
Retrieval Augmented Generation (RAG) is a technique that combines the power of large language models (LLMs) with external knowledge sources to improve the quality and relevance of generated content. There are a couple of reasons why RAG is interesting:
-
LLMs are not good at knowing the latest versions: For instance, for an LLM to keep up with the version of software libraries is very hard because they are updated frequently. Using the RAG pattern we can consult an external system our vector database to get the latest information.
-
Reducing Cost: Every single input and output token from an LLM costs money. By using RAG we can reduce the amount of tokens we send to the LLM by only sending the relevant parts of a document instead of the entire document, or sending the right information right away so the LLM does not need to generate multiple responses to get to the right answer.
-
Mitigating Hallucinations: LLMs are known to hallucinate information, meaning they can generate plausible-sounding but incorrect or fabricated content. There are many sources of hallucinations but one is that let’s say there is not enough data about a specific topic in the training data. By using RAG we can provide the LLM with accurate and relevant information from trusted sources, reducing the likelihood of hallucinations.
How RAG Pattern Works?
There are two main phases, first is the feed phase or feed process where we will ingest data, like documents or web pages, into a vector database. During this phase, the data is processed to create embeddings, which are numerical representations of the content that capture its semantic meaning. These embeddings are then stored in the vector database, allowing for efficient retrieval based on similarity.
Second phase is the retrieval part. Both phases are illustrated in the following diagram:
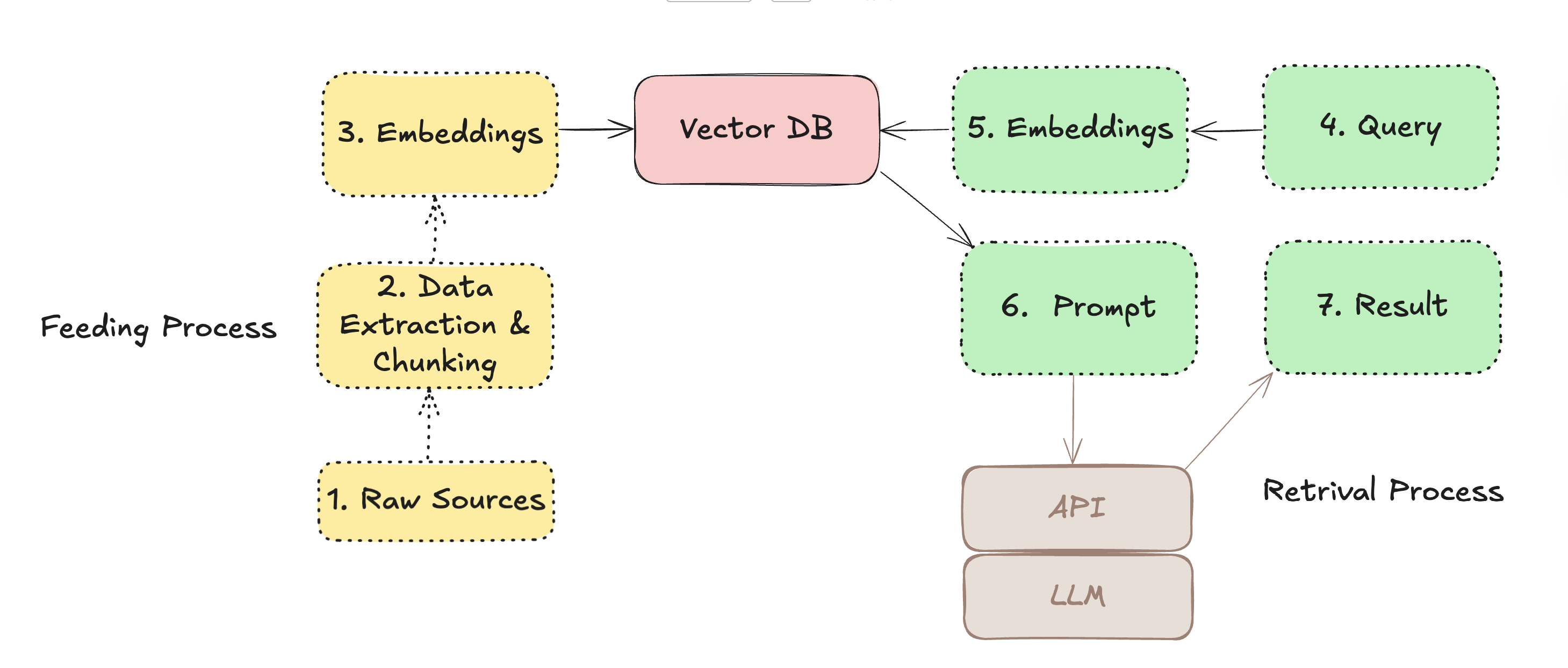
For the retrieval phase, we need a given query or text, which we turn into embeddings using the same model we used for the feed phase. Then we use these embeddings to search the vector database for similar embeddings, which correspond to relevant documents or pieces of information. The retrieved documents are then combined with whatever data is necessary or instructions to form a prompt that is sent to the LLM. The LLM uses this context to generate a response that is more informed and relevant to the query.